Introduction
In my previous post, I looked at techniques R offers to forecast stock prices. I learned how to decompose time series data to separate cyclical and long-term trends. I decided to further my research by investigating the relationship between oil futures and the current oil price. I proved that when current oil quotes are low, oil futures will tend to be consistently higher than the current quote. When oil prices are high, there is a greater degree of inconsistency. For the most part, the expectation was that the price would drop.
I also proved that the correlation between oil futures and the current oil price is a good indicator of the public's confidence that oil prices will continue in its current path. The average correlation between 2005 - 2016 is 0.71. An indicator of crude oil surplus is a decrease in correlation between the continuously compounded returns of oil and oil futures. The correlation was around 0.5 during 2007 financial crisis. Confidence in the oil market has been steadily rising since 2015. The increase in positive correlation while oil prices are decreasing means that the public is confident that the prices of oil will continue to drop.
Technique
Like my previous post, all my data comes from Quandl API. For oil quotes, I relied on the OPEC Basket Price. My values for the daily crude oil futures came from Quandl. As approximation, I averaged the open and close price.
library("Quandl")
OilFuture = Quandl("CHRIS/CME_CL1",trim_start="01-02-2004", trim_end="10-01-2016", type="zoo")
Oil = Quandl("OPEC/ORB", trim_start="01-02-2004", trim_end="10-01-2016", type="zoo")
AvgOilFuture = ((OilFuture[,2]+OilFuture[,1])/2)
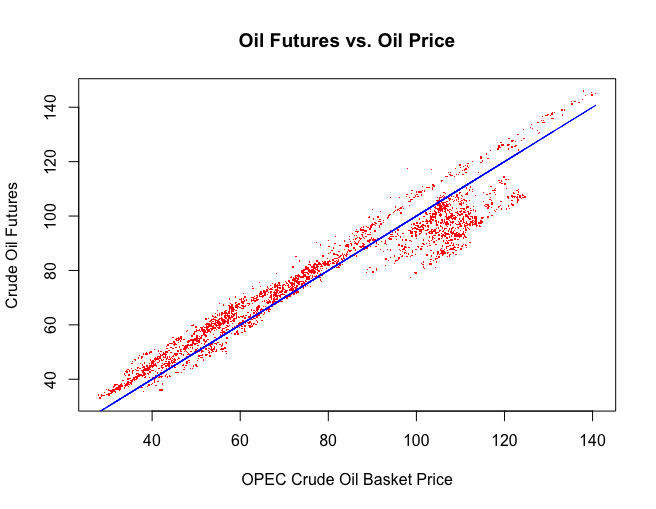 |
| Figure 1, Oil Futures vs. Oil |
First, I wanted a high level view of what I wanted to accomplish. I wanted to compare OPEC prices against Oil Futures. By comparing oil futures against oil prices from 2004 to 2016, I was able to gain some back-of-the-envelope insights (Figure 1). The blue represents the expectation that future oil prices will equal the current price.
- At low prices (<$80), the expectation was that the prices will increase.
- At high prices (>$80), the expectation had greater degree of uncertainty. For the most part, the expectation was that the price would drop.
I got the idea of converting the price to continuously compounded returns from an excellent piece by Guangming Lang. Converting the price to returns meant looking at the rate of increase as opposed to the prices themselves.
plot(MergedOil[,1],MergedOil[,2],pch=".",col="red",main = "Oil Futures vs. Oil Price",xlab = "OPEC Crude Oil Basket Price",ylab = "Crude Oil Futures")
lines(MergedOil[,1],MergedOil[,1],col="blue")
 |
| Figure 2, Experimenting with Moving Averages |
I experimented with different widths in Figure 2. At 5 points, short-term fluctuations are not smoothed out. At 500 points, long-term trends are erased. 100 points would be the optimal width.
plot(rollapply(ccret[,1],5,mean),col='red',xlab = "Year",ylab="Continuously Compounded Returns",main = "Returns from OPEC Basket Price with Moving Average")
legend('top', c("5 Points","50 Points","100 Points","500 Points"), lty=1, col=c('red','black', 'blue', 'green',' brown'), bty='n', cex=.9)
lines(rollapply(ccret[,1],50,mean),col='black')
lines(rollapply(ccret[,1],100,mean),col='blue')
lines(rollapply(ccret[,1],500,mean),col='green')
 |
| Figure 3, Comparison between Oil and Oil Futures |
The next step was to compare the actual crude oil price and its future - with the moving average applied to remove any noise. Figure 3 shows that returns from both datasets are pretty much equal: when the future's quote increase, the current oil's quote increases proportionally. There is actually a way to quantify the correlation between both datasets.
plot(movingavg[,1], xlab="Time", ylab="Continuously Compounded Returns",main="Comparison between Crude Oil Current Prices and Futures")
lines(movingavg[,2],col="red")
legend('topleft', c("OPEC Crude Oil Basket Price","Crude Oil Futures"), lty=1, col=c('black','red'), bty='n', cex=.9)
 |
| Figure 4, Correlation between Oil and Oil Futures |
Figure 4 illustrates the correlation between Oil and Oil Futures. I can determine that that there is an overall moderate positive correlation between the two datasets. Additionally, I can see that the weakest relationship were during the 2007-2008 financial crisis and 2014-2015 oil glut. A weak relationship means that values are more spread around the expected value.
Simply put, a weak positive relationship means that the investors are uncertain that the oil market will continue in its current trajectory. I can also determine that the 2007 recession took the investing public by surprise (judging by the steep fall) but confidence was decreasing well before the 2014-2015 oil glut
Also, the correlation has been growing stronger since 2015. This means that the belief that the price of oil will stay in its current trajectory has been growing steadily stronger. Unfortunately, the current trajectory for the price of oil is decreasing.
correlate_oil= function(x) cor(x)[1, 2]
oil_cor= rollapply(ccret, width=100, FUN=correlate_oil, by.column=FALSE, align="right")
plot(oil_cor,ylab="Correlation",xlab="Time",main="Correlation between Continuously Compounded Returns of Oil and Oil Futures")
I was pleasantly surprised about my conclusions. I learned that during major economic crisis, the public will lose confidence that the oil price will increase. I also learned that the 2014-2015 oil glut could have been predicted as confidence started to dip around 2013. This is surprising as major oil companies should have prepared for this by reducing production instead of later laying off employees. In July 2016, Calgary, a major city dependent on the petroleum industry, had an unemployment rate close to 9% because of the layoffs.
Next steps into my research will be to look at commodities to forecast oil prices - such as gold, copper and even rice.
Resources
Freaknomics . (2008, July ). Forecasting Oil
Prices: It’s Easy to Beat the Experts. Retrieved November 2016 , from
Freaknomics :
http://freakonomics.com/2008/07/21/forecasting-oil-prices-its-easy-to-beat-the-experts/
Lang, G. (2014, October ). Analyze
Stock Price Data Using R (Part 3) . Retrieved November 2016, from Master R
: http://masterr.org/r/analyze-stock-price-data-using-r-part3/
Ron Alquist, L. K.
(2011). Forecasting the Price of Oil. Board of Governors of the Federal
Reserve System.













